Wrangling and analysis of social media data in Python: can dogs pics be engaging too?
WeRateDogs is a Twitter account that rates people’s dogs with a humorous comment about the dog. This project is all about wrangling and analysing data related to WeRateDogs.
Cats have long been favourites on the internet, but how about dogs? In this project I wrangled social media data to be bale to analys the output and user engagement of the WeRateDogs Twitter account.
Project purpose
The overall aim was to carry out a full process of data wrangling and analysis through all the different project stages in Python.
This was the first project I did that involved social media data obtained via an API. I carried it out in the second term of my Data Analyst course.
Process
The main steps were:
- Data wrangling:
- Gathering data (from 3 sources)
- Assessing data (for quality and structure, then a list of problems and fixes was made)
- Cleaning data (the list of fixes was implemented)
- Storage (cleaned data sets were combined and saved as a .csv file)
- Analyzing and visualizing cleaned data
- Reporting
Data from three sources and in a variety of formats were used. After assessing its quality and tidiness, data was subjected to data cleaning and then combined into a single dataset. This was then analysed and visualised.
Data sets and tools
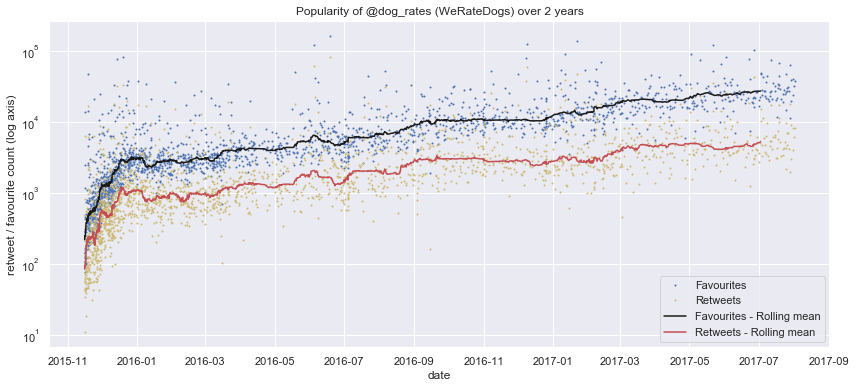
I obtained all the tweets from the WeRateDogs feed as JSON data via the Twitter API using Tweepy. The json library was then used to extract information on user engagement including tweet author, number of favourties, retweets, as well as the tweet ID.
Two archive files were provided, one containing image predictions of dog pictures that had been tweeted by the WeRateDogs account ; another archive file contained tweet data from the same account. The three files were assessed for data quality and tidiness, then cleaned, and merged.
I used Python to wrangle data programmatically and prepare it for deeper analysis using Python libraries particularly Pandas. Other Python libraries I used in the project were numpy ; requests ; tweepy ; json ; matplotlib.pyplot ; seaborn ; scipy. All work was carried out in a Jupyter notebook.
Links & files:
- Jupyter notebook containing all the data wrangling, analysis and visualsations steps
- Act_report.pdf: Insights and visualizations from the wrangled data.
- Wrangle_report.pdf: Describes wrangling efforts plus some reflections